目录
Python2.7字符编码详解
标签: Python 字符编码
声明
本文主要介绍字符编码基础知识,以及Python2.7字符编码实践。
注意,文中关于Python字符编码的解释和建议适用于Python2.x版本,而不适用于3.x版本。 本文同时也发布于,阅读体验可能更好。一. 字符编码基础
为明确概念,将字符集的分为以下4个层次:
- 抽象字符清单(Abstract Character Repertoire, ACR): 待编码文字和符号的无序集合,包括各国文字、标点、图形符号、数字等。
- 已编码字符集(Coded Character Set, CCS): 从抽象字符清单到非负整数码点(code point)集合的映射。
- 字符编码格式(Character Encoding Form, CEF): 从码点集合到指定宽度(如32比特整数)编码单元(code unit)的映射。
- 字符编码方案(Character Encoding Scheme, CES): 从编码单元序列集合(一个或多个CEF)到一个串行化字节序列的可逆转换。
1.1 抽象字符清单(ACR)
抽象字符清单可理解为无序的抽象字符集合。"抽象"意味着字符对象并非直接存在于计算机系统中,也未必是真实世界中具体的事物,例如"a"和"为"。抽象字符也不必是图形化的对象,例如控制字符"0宽度空格"(zero-width space)。
大多数字符编码的清单较小且处于"fixed"状态,即不再追加新的抽象字符(否则将创建新的清单);其他清单处于"open"状态,即允许追加新字符。例如,Unicode旨在成为通用编码,其字符清单本身是开放的,以便周期性的添加新的可编码字符。
1.2 已编码字符集(CCS)
已编码字符集是从抽象字符清单到非负整数(范围不必连续)的映射。该整数称为抽象字符被赋予的码点(code point,或称码位code position),该字符则称为已编码字符。注意,码点并非比特或字节,因此与计算机表示无关。码点的取值范围由编码标准限定,该范围称为编码空间(code space)。在一个标准中,已编码字符集也称为字符编码、已编码字符清单、字符集定义或码页(code page)。
在CCS中,需要明确定义已编码字符相关的任何属性。通常,标准为每个已编码字符分配唯一的名称,例如“拉丁小写字母A(LATIN SMALL LETTER A)”。当同一个抽象字符出现在不同的已编码字符集且被赋予不同的码点时,通过其名称可无歧义地标识该字符。但实际应用中厂商或其他标准组织未必遵循这一机制。Unicode/10646出现后,其通用性使得该机制近乎过时。
某些工作在CCS层的工业标准将字符集标准化(可能也包括其名称或其他属性),但并未将它们在计算机中的编码表示进行标准化。例如,东亚字符标准GB2312-80(简体中文)、CNS 11643(繁体中文)、JIS X 0208(日文),KS X 1001(韩文)。这些标准使用与之独立的标准进行字符编码的计算机表示,这将在CEF层描述。
1.3 字符编码格式(CEF)
字符编码格式是已编码字符集中的码点集合到编码单元(code unit)序列的映射。编码单元为整数,在计算机架构中占据特定的二进制宽度,例如7比特、8比特等(最常用的是8/16/32比特)。编码格式使字符表示为计算机中的实际数据。
编码单元的序列不必具有相同的长度。序列具有相同长度的字符编码格式称为固定宽度(或称等宽),否则称为可变宽度(或称变长)。固定宽度的编码格式示例如下:
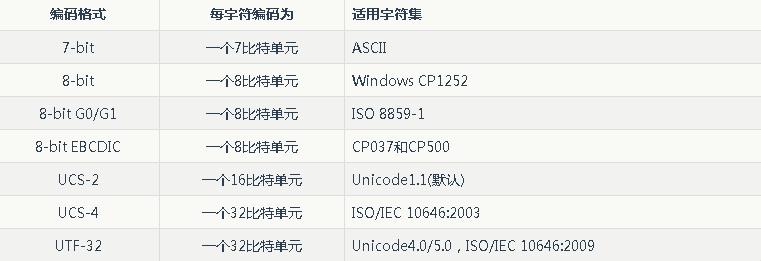 可变宽度的编码格式示例如下:
可变宽度的编码格式示例如下:
一个码点未必对应一个编码单元。很多编码格式将一个码点映射为多个编码单元的序列,例如微软码页932(日文)或950(繁体中文)中一个字符编码为两个字节。然而,码点到编码单元序列的映射是唯一的。
除东亚字符集外,所有传统字符集的编码空间都未超出单字节范围,因此它们通常使用相同的编码格式(对此不必区分码点和编码单元)。
某些字符集可使用多种编码格式。例如,GB2312-80字符集可使用GBK编码、ISO 2022编码或EUC编码。此外,有的编码格式可用于多种字符集,例如ISO 2022标准。ISO 2022为其支持的每个特定字符集分配一个特定的转义序列(escape sequence)。默认情况下,ISO 2022数据被解释为ASCII字符集;遇到任一转义序列时则以特定的字符集解释后续的数据,直到遇到一个新的转义序列或恢复到默认状态。ISO 2022标准旨在提供统一的编码格式,以期支持所有字符集(尤其是中日韩等东亚文本)。但其数据解释的控制机制相当复杂,且很多,仅在日本使用普遍。
Unicode标准并未依照惯例,将每个字符直接映射为特定模式的编码比特序列。相反地,Unicode先将字符映射为码点,再将码点以各种方式各种编码单元编码。通过将CCS和CEF分离,Unicode的编码格式更为灵活(如UCS-X和UTF-X)。
以下详细介绍中文编码时常见的字符集及其编码格式。为符合程序员既有概念,此处并未严格区分CCS与CEF。但应认识到,ASCII/EASCII和GB2312/GBK/GB18030既是CCS也是CEF;区位码和Unicode是CCS;EUC-CN/ISO-2022-CN/HZ、UCS-2/UCS-4、UTF-8/UTF-16/UTF-32是CEF。
注意,中文编码还有交换码、输入码、机内码、输出码等概念。交换码又称国标码,用于汉字信息交换,即GB2312-80(区位码加0x20)。输入码又称外码,即使用英文键盘输入汉字时的编码,大体分为音码、形码、数字码和音形码四类。例如,汉字"肖"用拼音输入时外码为xiao,用区位码输入时为4804,用五笔字型输入时为IEF。机内码又称内码或汉字存储码,即计算机操作系统内部存储、处理和交换汉字所用的编码(GB2312/GBK)。尽管同一汉字的输入码有多种,但其内码相同。输出码又称字型码,即根据汉字内码找到字库中的地址,再将其点阵字型在屏幕上输出。
早期Windows系统默认的内码与语言相关,英文系统内码为ASCII,简体中文系统内码为GB2312或GBK,繁体中文系统内码为BIG5。Windows NT+内核则采用Unicode编码,以便支持所有语种字符。但由于现有的大量程序和文档都采用某种特定语言的编码,因此微软使用码页适应各种语言。例如,GB2312码页是CP20936,GBK码页是CP936,BIG5码页是CP950。此时,"内码"的概念变得模糊。微软一般将缺省码页指定的编码称为内码,在特殊场合也称其内码为Unicode。
1.3.1 ASCII(初创)
1.3.1.1 ASCII
ASCII(American Standard Code for Information Interchange)为7比特编码,编码范围是0x00-0x7F,共计128个字符。ASCII字符集包括英文字母、阿拉伯数字、英式标点和控制字符等。其中,0x00-0x1F和0x7F为33个无法打印的控制字符。
ASCII编码设计良好,如数字和字母连续排列,数字对应其16进制码点的低四位,大小写字母可通过一个bit的翻转而相互转化,等等。初创标准的影响力如此之强,以致于后世所有广泛应用的编码标准都要兼容ASCII编码。
在Internet上使用时,ASCII的别名(不区分大小写)有ANSI_X3.4-1968、iso-ir-6、ANSI_X3.4-1986、ISO_646.irv:1991、ISO646-US、US-ASCII、IBM367、cp367和csASCII。
1.3.1.2 EASCII
EASCII扩展ASCII编码字节中闲置的最高位,即8比特编码,以支持其他非英语语言。EASCII编码范围是0x00-0xFF,共计256个字符。
不同国家对0x80-0xFF这128个码点的不同扩展,最终形成15个ISO-8859-X编码标准(X=1~11,13~16),涵盖拉丁字母的西欧语言、使用西里尔字母的东欧语言、希腊语、泰语、现代阿拉伯语、希伯来语等。例如为西欧语言而扩展的字符集编码标准编号为ISO-8859-1,其别名为cp819、csISO、Latin1、ibm819、iso_8859-1、iso_8859-1:1987、iso8859-1、iso-ir-100、l1、latin-1。
ISO-8859-1标准中,0x00-0x7F之间与ASCII字符相同,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。其字符集详见。在Windows记事本里,通过ALT+Latin1码点10进制值可输入相应字符。
ISO-8859-1编码空间覆盖单字节所有取值,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会造成数据丢失。换言之,可将任何编码的字节流视为ISO-8859-1编码。因此,很多传输(如Java网络传输)和存储(如MySQL数据库)过程默认使用该编码。注意,ISO-8859-X编码标准互不兼容。例如,0xA3在Latin1编码中代表英镑符号"£",在Latin2编码中则代表"Ł"(带斜线的大写L)。而且,这两个符号无法同时出现在一个文件内。
ASCII和EASCII均为单字节编码(Single Byte Character System, SBCS),即使用一个字节存放一个字符。只支持ASCII码的系统会忽略每个字节的最高位,只认为低7位是有效位。
1.3.2 MBCS/DBCS/ANSI(本地化)
由于单字节能表示的字符太少,且同时也需要与ASCII编码保持兼容,所以不同国家和地区纷纷在ASCII基础上制定自己的字符集。这些字符集使用大于0x80的编码作为一个前导字节,前导字节与紧跟其后的第二(甚至第三)个字节一起作为单个字符的实际编码;而ASCII字符仍使用原来的编码。以汉字为例,字符集GB2312/BIG5/JIS使用两个字节表示一个汉字,使用一个字节表示一个ASCII字符。这类字符集统称为ANSI字符集,正式名称为MBCS(Multi-Byte Chactacter Set,多字节字符集)或DBCS(Double Byte Charecter Set,双字节字符集)。在简体中文操作系统下,ANSI编码指代GBK编码;在日文操作系统下,ANSI编码指代JIS编码。
ANSI编码之间互不兼容,因此Windows操作系统使用码页转换表技术支持各字符集的显示问题,即通过指定的转换表将非Unicode的字符编码转换为同一字符对应的系统内部使用的Unicode编码。可在"区域和语言选项"中选择一个代码页作为非Unicode编码所采用的默认编码方式,如936为简体中文GBK,950为繁体中文Big5。但当信息在国际间交流时,仍无法将属于两种语言的文本以同一种ANSI编码存储和传输。
1.3.2.1 GB2312
GB2312为中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集 基本集》,由中国国家标准总局于1980年发布,1981年5月1日开始实施。标准号是GB 2312—1980。
GB2312标准适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆地区及新加坡,简称国标码。GB2312标准共收录6763个简体汉字,其中一级汉字3755个,二级汉字3008个。此外,GB2312还收录数学符号、拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等682个字符。这些非汉字字符有些来自ASCII字符集,但被重新编码为双字节,并称为"全角"字符;ASCII原字符则称为"半角"字符。例如,全角a编码为0xA3E1,半角a则编码为0x61。
GB2312是基于区位码设计的。区位码将整个字符集分成94个区,每区有94个位。每个区位上只有一个字符,因此可用汉字所在的区和位来对其编码。
区位码中01-09区为特殊符号。16-55区为一级汉字,按拼音字母/笔形顺序排序;56-87区为二级汉字,按部首/笔画排序。10-15区及88-94区为未定义的空白区。
区位码是一个四位的10进制数,如1601表示16区1位,对应的字符是“啊”。Windows系统支持区位输入法,例如通过"中文(简体) - 内码"输入法小键盘输入1601可得到"啊",输入0528则得到"ゼ"。
区位码可视为已编码字符集,其编码格式可为EUC-CN(常用)、ISO-2022-CN(罕用)或HZ(用于新闻组)。ISO-2022-CN和HZ针对早期只支持7比特ASCII的系统而设计,且因为使用转义序列而存在诸多缺点。ISO-2022标准将区号和位号加上32,以避开ASCII的控制符区。而EUC(Extended Unix Code)基于ISO-2022区位码的94x94编码表,将其编码字节的最高位置1,以简化日文、韩文、简体中文表示。可见,EUC区(位) = 原始区(位)码 + 32 + 0x80 = 原始区(位)码 + 0xA0。这样易于软件识别字符串中的特定字节,例如小于0x7F的字节表示ASCII字符,两个大于0x7F的字节组合表示一个汉字。EUC-CN是GB2312最常用的表示方法,可认为通常所说的GB2312编码就指EUC-CN或EUC-GB2312。
综上,GB2312标准中每个汉字及符号以两个字节来表示。第一个字节称为高字节(也称区字节),使用0xA1-0xF7(将01-87区的区号加上0xA0);第二个字节称为低字节(也称位字节),使用0xA1-0xFE(将01-94加上 0xA0)。汉字区的高字节范围是0xB0-0xF7,低字节范围是0xA1-0xFE,占用码位72*94=6768。其中有5个空位是D7FA-D7FE。例如,汉字"肖"的区位码为4804,将其区号和位号分别加上0xA0得到0xD0A4,即为GB2312编码。汉字的GB2312编码详见,也可通过查询。
GB2312所收录的汉字已覆盖中国大陆99.75%的使用频率,但不包括人名、地名、古汉语等方面出现的生僻字。
1.3.2.2 GBK
GBK全称为《汉字内码扩展规范》 ,于1995年发布,向下完全兼容GB2312-1980国家标准,向上支持ISO 10646.1国际标准。该规范收录Unicode基本多文种平面中的所有CJK(中日韩)汉字,并包含BIG5(繁体中文)编码中的所有汉字。其编码高字节范围是0x81-0xFE,低字节范围是0x40-0x7E和0x80-0xFE,共23940个码位,收录21003个汉字和883个图形符号。
GBK码位空间可划分为以下区域:
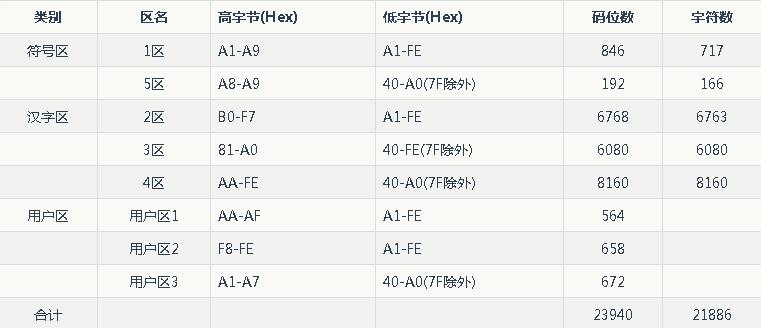 注意,码位空间中的码位并非都已编码,例如0xA2E3和0xA2E4并未定义编码。
注意,码位空间中的码位并非都已编码,例如0xA2E3和0xA2E4并未定义编码。 为扩展码位空间,GBK规定只要高字节大于0x7F就表示一个汉字的开始。但低字节为0x40-0x7E的GBK字符会占用ASCII码位,而程序可能使用该范围内的ASCII字符作为特殊符号,例如将反斜杠""作为转义序列的开始。若定位这些符号时未判断是否属于某个GBK汉字的低字节,就会造成误判。
1.3.2.3 GB18030
GB18030全称为国家标准GB18030-2005《信息技术中文编码字符集》,是中国计算机系统必须遵循的基础性标准之一。GB18030与GB2312-1980完全兼容,与GBK基本兼容,收录GB 13000及Unicode3.1的全部字符,包括70244个汉字、多种中国少数民族字符、GBK不支持的韩文表音字符等。
GB2312和GBK均为双字节等宽编码,若算上兼容ASCII所支持的单字节,也可视为单字节和双字节混合的变长编码。GB18030编码是变长编码,每个字符可用一个、两个或四个字节表示。GB18030码位定义如下:
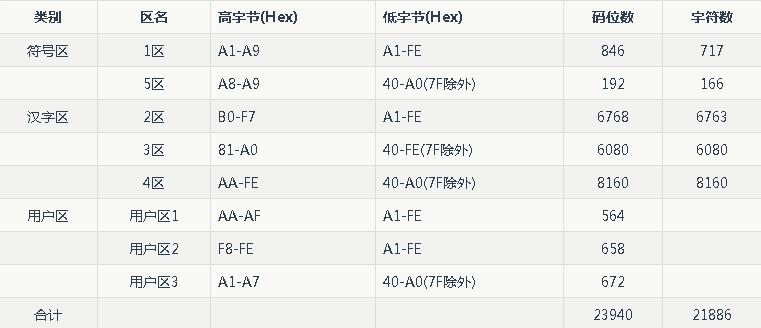 可见,GB18030的单字节编码范围与ASCII相同,双字节编码范围则与GBK相同。此外,GB18030有1611668个码位,多于Unicode的码位数目(1114112)。因此,GB18030有足够的空间映射Unicode的所有码位。
可见,GB18030的单字节编码范围与ASCII相同,双字节编码范围则与GBK相同。此外,GB18030有1611668个码位,多于Unicode的码位数目(1114112)。因此,GB18030有足够的空间映射Unicode的所有码位。 GBK编码不支持欧元符号"€",Windows CP936码页使用0x80表示欧元,GB18030编码则使用0xA2E3表示欧元。
从ASCII、GB2312、GBK到GB18030,编码向下兼容,即相同字符编码也相同。这些编码可统一处理英文和中文,区分中文编码的方法是高字节的最高位不为0。
1.3.3 Unicode(国际化)
Unicode字符集由多语言软件制造商组成的统一码联盟(Unicode Consortium)与国际标准化组织的ISO-10646工作组制订,为各种语言中的每个字符指定统一且唯一的码点,以满足跨语言、跨平台转换和处理文本的要求。
最初统一码联盟和ISO组织试图独立制订单一字符集,从Unicode 2.0后开始协作和共享,但仍各自发布标准(每个Unicode版本号都能找到对应的ISO 10646版本号)。两者的字符集相同,差异主要是编码格式。
Unicode码点范围为0x0-0x10FFFF,共计1114112个码点,划分为编号0-16的17个字符平面,每个平面包含65536个码点。其中编号为0的平面最为常用,称为基本多语种平面(Basic Multilingual Plane, BMP);其他则称为辅助语言平面。Unicode码点的表示方式是"U+"加上16进制的码点值,例如字母"A"的Unicode编码写为U+0041。通常所说的Unicode字符多指BMP字符。其中,U+0000到U+007F的范围与ASCII字符完全对应,U+4E00到U+9FA5的范围定义常用的20902个汉字字符(这些字符也在GBK字符集中)。
ISO-10646标准将Unicode称为通用字符集(Universal Character Set, UCS),其编码格式以"UCS-"加上编码所用的字节数命名。例如,UCS-2使用双字节编码,仅能表示BMP中的字符;UCS-4使用四字节编码(实际只用低31位),可表示所有平面的字符。UCS-2中每两个字节前再加上0x0000就得到BMP字符的UCS-4编码。这两种编码格式都是等宽编码,且已经过时。另一种编码格式来自Unicode标准,名为通用编码转换格式(Unicode Translation Format, UTF),其编码格式以"UTF-"加上编码所用的比特数命名。例如,UTF-8以8比特单字节为单位,BMP字符在UTF-8中被编码为1到3个字节,BMP之外的字符则映射为4个字节;UTF-16以16比特双字节为单位,BMP字符为2个字节,BMP之外的字符为4个字节;UTF-32则是定长的四字节。这三种编码格式均都可表示所有平面的字符。
UCS-2不同于GBK和BIG5,它是真正的等宽编码,每个字符都使用两个字节,这种特性在字符串截断和字符数计算时非常方便。UTF-16是UCS-2的超集,在BMP平面内UCS-2完全等同于UTF-16。由于BMP之外的字符很少用到,实际使用中UCS-2和UTF-16可近似视为等价。类似地,UCS-4和UTF-32是等价的,但目前使用比较少。
Windows系统中Unicode编码就指UCS-2或UTF-16编码,即英文字符和中文汉字均由两字节表示,也称为宽字节。但这种编码对互联网上广泛使用的ASCII字符而言会浪费空间,因此互联网字符编码主要使用UTF-8。
1.3.3.1 UTF-8
UTF-8是一种针对Unicode的可变宽度字符编码,可表示Unicode标准中的任何字符。UTF-8已逐渐成为电子邮件、网页及其他存储或传输文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。
UTF-8使用1-4个字节为每个字符编码,其规则如下(x表示可用编码的比特位):
 亦即: 1) 对于单字节符号,字节最高位置为0,后面7位为该符号的Unicode码。这与128个US-ASCII字符编码相同,即兼容ASCII编码。因此,原先处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。 2)对于n字节符号(n>1),首字节的前n位均置为1,第n+1位置为0,后面字节的前两位一律设为10。其余二进制位为该符号的Unicode码。 可见,若首字节最高位为0,则表明该字节单独就是一个字符;若首字节最高位为1,则连续出现多少个1就表示当前字符占用多少个字节。
亦即: 1) 对于单字节符号,字节最高位置为0,后面7位为该符号的Unicode码。这与128个US-ASCII字符编码相同,即兼容ASCII编码。因此,原先处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。 2)对于n字节符号(n>1),首字节的前n位均置为1,第n+1位置为0,后面字节的前两位一律设为10。其余二进制位为该符号的Unicode码。 可见,若首字节最高位为0,则表明该字节单独就是一个字符;若首字节最高位为1,则连续出现多少个1就表示当前字符占用多少个字节。 以中文字符"汉"为例,其Unicode编码是U+6C49,位于0x0800-0xFFFF之间,因此"汉"的UTF-8编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制0110 110001 001001,用这个比特流依次代替x,得到11100110 10110001 10001001,即"汉"的UTF-8编码为0xE6B189。注意,常用汉字的UTF-8编码占用3个字节,中日韩超大字符集里的汉字占用4个字节。
考虑到辅助平面字符很少使用,UTF-8规则可简记为(0),(110,10),(1110,10,10)或(00-7F),(C0-DF,80-BF),(E0-E7,80-BF,80-BF)。即,单字节编码的字节取值范围为0x00-0x7F,双字节编码的首字节为0xC0-0xDF,三字节编码的首字节为0xE0-0xEF。这样只要看到首字节范围就知道编码字节数,可大大简化算法。
UTF-8具有(包括但不限于)如下:
- ASCII文本串也是合法的UTF-8文本,因此所有现存的ASCII文本不需要转换,且仅支持7比特字符的软件也可处理UTF-8文本。
- UTF-8可编码任意Unicode字符,而无需选择码页或字体,且支持同一文本内显示不同语种的字符。
- Unicode字符串经UTF-8编码后不含零字节,因此可由C语言字符串函数(如strcpy)处理,也能通过无法处理零字节的协议传输。
- UTF-8编码较为紧凑。ASCII字符占用一个字节,与ASCII编码相当;拉丁字符占用两个字节,与UTF-16相当;中文字符一般占用三个字节,虽逊于GBK但优于UTF-32。
- UTF-8为自同步编码,很容易扫描定位字符边界。若字节在传输过程中损坏或丢失,根据编码规律很容易定位下一个有效的UTF-8码点并继续处理(再同步)。 许多双字节编码(尤其是GB2312这种高低字节均大于0x7F的编码),一旦某个字节出现差错,就会影响到该字节之后的所有字符。
- UTF-8字符串可由简单的可靠地识别。合法的UTF-8字符序列不可能出现最高位为1的单个字节,而出现最高位为1的字节对的概率仅为11.7%,这种概率随序列长度增长而减小。因此,任何其他编码的文本都不太可能是合法的UTF-8序列。
1.3.3.2 UTF-16
当Unicode字符码点位于BMP平面(即小于U+10000)时,UTF-16将其编码为1个16比特编码单元(即双字节),该单元的数值与码点值相同。例如,U+8090的UTF-16编码为0x8090。同时可见,UTF-16不兼容ASCII。
当Unicode字符码点超出BMP平面时,UTF-16编码较为复杂,详见。
UTF-16编码在空间效率上比UTF-32高两倍,而且对于BMP平面内的字符串,可在常数时间内找到其中的第N个字符。
1.3.3.3 UTF-32
UTF-32将Unicode字符码点编码为1个32比特编码单元(即四字节),因此空间效率较低,不如其它Unicode编码应用广泛。
UTF-32编码可在常数时间内定位Unicode字符串里的第N个字符,因为第N个字符从第4×Nth个字节开始。
1.3.3.4 编码适用场景
当程序需要与现存的那些专为8比特数据而设计的实现协作时,应选择UTF-8编码;当程序需要处理BMP平面内的字符(尤其是东亚语言)时,应选择UTF-16编码;当程序需要处理单个字符(如接收键盘驱动产生的一个字符),应选择UTF-32编码。因此,许多应用程序选用UTF-16作为其主要的编码格式,而互联网则广泛使用UTF-8编码。
1.4 字符编码方案(CES)
字符编码方案主要关注跨平台处理编码单元宽度超过一个字节的数据。
大多数等宽的单字节CEF可直接映射为CES,即每个7比特或8比特编码单元映射为一个取值与之相同的字节。大多数混合宽度的单字节CEF也可简单地将CEF序列映射为字节,例如UTF-8。UTF-16因为编码单元为双字节,串行化字节时必须指明字节顺序。例如,UTF-16BE以大字节序串行化双字节编码单元;UTF-16LE则以小字节序串行化双字节编码单元。
早期的处理器对内存地址解析方式存在差异。例如,对于一个双字节的内存单元(值为0x8096),PowerPC等处理器以内存低地址作为最高有效字节,从而认为该单元为U+8096(肖);x86等处理器以内存高地址作为最高有效字节,从而认为该单元为U+9680(隀)。前者称为大字节序(Big-Endian),后者称为小字节序(Little-Endian)。无论是两字节的UCS-2/UTF-16还是四字节的UCS-4/UTF-32,既然编码单元为多字节,便涉及字节序问题。
Unicode将码点U+FEFF的字符定义为字节顺序标记(Byte Order Mark, BOM),而字节颠倒的U+FFFE在UTF-16中并非字符,(0xFFFE0000)对UTF-32而言又超出编码空间。因此,通过在Unicode数据流头部添加BOM标记,可无歧义地指示编码单元的字节顺序。若接收者收到0xFEFF,则表明数据流为UTF-16编码,且为大字节序;若收到0xFEFF,则表明数据流为小字节序的UTF-16编码。注意,U+FEFF本为零宽不换行字符(ZERO WIDTH NO-BREAK SPACE),在Unicode数据流头部以外出现时,该字符被视为零宽不换行字符。自Unicode3.2标准起废止U+FEFF的不换行功能,由新增的U+2060(Word Joiner)代替。
不同的编码方案对零宽不换行字符的解析如下:
 UTF-16和UTF-32编码默认为大字节序。UTF-8以字节为编码单元,没有字节序问题,BOM用于表明其编码格式(signature),但不建议如此。因为UTF-8编码特征明显,无需BOM即可检测出是否UTF-8序列(序列较短时可能不准确)。
UTF-16和UTF-32编码默认为大字节序。UTF-8以字节为编码单元,没有字节序问题,BOM用于表明其编码格式(signature),但不建议如此。因为UTF-8编码特征明显,无需BOM即可检测出是否UTF-8序列(序列较短时可能不准确)。 微软建议所有Unicode文件以BOM标记开头,以便于识别文件使用的编码和字节顺序。例如,Windows记事本默认保存的编码格式是ANSI(简体中文系统下为GBK编码),不添加BOM标记。另存为"Unicode"编码(Windows默认Unicode编码为UTF-16LE)时,文件开头添加0xFFFE的BOM;另存为"Unicode big endian"编码时,文件开头添加0xFEFF的BOM;另存为"UTF-8"编码时,文件开头添加0xEFBBBF的BOM。使用UEStudio打开ANSI编码的文件时,右下方行列信息后显示"DOS";打开Unicode文件时显示"U-DOS";打开Unicode big endian文件时显示"UBE-DOS";打开UTF-8文件时显示"U8-DOS"。
借助BOM标记,记事本在打开文本文件时,若开头没有BOM,则判断为ANSI编码;否则根据BOM的不同判断是哪种Unicode编码格式。然而,即使文件开头没有BOM,记事本打开该文件时也会先用UTF-8检测编码,若符合UTF-8特征则以UTF-8解码显示。考虑到某些GBK编码序列也符合UTF-8特征,文件内容很短时可能会被错误地识别为UTF-8编码。例如,记事本中只写入"联通"二字时,以ANSI编码保存后再打开会显示为黑框;而只写入"姹塧"时,再打开会显示为"汉a"。若再输入更多汉字并保存,然后打开清空重新输入"联通",保存后再打开时会正常显示,这说明记事本确实能"记事"。当然,也可通过记事本【文件】|【打开】菜单打开显示为黑框的"联通"文件,在"编码"下拉框中将UTF-8改为ANSI,即可正常显示。
Unicode标准并未要求或建议UTF-8编码使用BOM,但确实允许BOM出现在文件开头。带有BOM的Unicode文件有时会带来一些问题:
- Linux/UNIX系统未使用BOM,因为它会破坏现有ASCII文件的语法约定。
- 某些编辑器不会添加BOM,或者可以选择是否添加BOM。
- 某些语法分析器可以处理字符串常量或注释中的UTF-8,但无法分析文件开头的BOM。
- 某些程序在文件开头插入前导字符来声明文件类型等信息,这与BOM的用途冲突。
综合起来,程序可通过一下步骤识别文本的字符集和编码:
1) 检查文本开头是否有BOM,若有则已指明文本编码。 2) 若无BOM,则查看是否有编码声明(针对Python脚本和XML文档等)。 3) 若既无BOM也无编码声明,则Python脚本应为ASCII编码,其他文本则需要猜测编码或请示用户。 记事本就是根据文本的特征来猜测其字符编码。缺点是当文件内容较少时编码特征不够明确,导致猜测结果不能完全精准。Word则通过弹出一个对话框来请示用户。例如,将"联通"文件右键以Word打开时,Word也会猜测该文件是UTF-8编码,但并不能确定,因此会弹出文件转换的对话框,请用户选择使文档可读的编码。这时无论选择"Windows(默认)"还是"MS-DOS"或是"其他编码"下拉框(初始显示UTF-8)里的简体中文编码,均能正常显示"联通"二字。注意,文本文件并不单指记事本纯文本,各种源代码文件也是文本文件。因此,编辑和保存源代码文件时也要考虑字符编码(除非仅使用ASCII字符),否则编译器或解释器可能会以错误的编码格式去解析源代码。
1.5 中文字符乱码(Mojibake)
乱码(mojibake)是指以非期望的编码格式解码文本时产生的混乱字符,通常表现为正常文本被系统地替换为其他书写系统中不相关的符号。当字符的二进制表示被视为非法时,可能被替换为通用替换字符U+FFFD。当多个连续字符的二进制编码恰好对应其他编码格式的一个字符时,也会产生乱码。这要么发生在不同长度的等宽编码之间(如东亚双字节编码与欧洲单字节编码),要么是因为使用变长编码格式(如UTF-8和UTF-16)。
本节不讨论因字体(font)或字体中字形(glyph)缺失而导致的字形渲染失败。这种渲染失败表现为整块的码点以16进制显示,或被替换为U+FFFD。
为正确再现被编码的原始文本,必须确保所编码数据与其编码声明一致。因为数据本身可被操纵,编码声明可被改写,两者不一致时必然产生乱码。
乱码常见于文本数据被声明为错误的编码,或不加编码声明就在默认编码不同的计算机之间传输。例如,通信协议依赖于每台计算机的编码设置,而不是与数据一起发送或存储元数据。
计算机的默认设置之所以不同,一部分是因为Unicode在操作系统家族中的部署不同,另一部分是因为针对人类语言的不同书写系统存在互不兼容的传统编码格式。目前多数Linux发行版已切换到UTF-8编码(如LANG=zh_CN.UTF-8),但Windows系统仍使用码页处理不同语言的文本文件。此外,若中文"汉字"以UTF-8编码,软件却假定文本以Windows1252或ISO-8859-1编码,则会错误地显示为"汉å—"或"æ±å"。类似地,在Windows简体中文系统(cp936)中手工创建文件(如"GNU Readline库函数的应用示例")时,文件名为gbk编码;而通过Samba服务复制到Linux系统时,文件名被改为utf-8编码。再通过fileZilla将文件下载至外部设备时,若外设默认编码为ISO-8859-1,则最终文件名会显示为乱码(如"GNU Readlineåºå½æ°çåºç¨ç¤ºä¾")。注意,通过Samba服务创建文件并编辑时,文件名为UTF-8编码,文件内容则为GBK编码。
以下介绍常见的乱码原因及解决方案。
1.5.1 未指定编码格式
若未指定编码格式,则由软件通过其他手段确定,例如字符集配置或编码特征检测。文本文件的编码通常由操作系统指定,这取决于系统类型和用户语言。当文件来自不同配置的计算机时,例如Windows和Linux之间传输文件,对文件编码的猜测往往是错的。一种解决方案是使用字节顺序标记(BOM),但很多分析器不允许源代码和其他机器可读的文本中出现BOM。另一种方案是将编码格式存入文件系统元数据中,支持扩展文件属性的文件系统可将其存为user.charset。这样,想利用这一特性的软件可去解析编码元数据,而其他软件则不受影响。此外,某些编码特征较为明显,尤其是UTF-8,但仍有许多编码格式难以区分,例如EUC-JP和Shift-JIS。总之,无论依靠字符集配置还是编码特征,都很容易误判。
1.5.2 错误指定编码格式
错误指定编码格式时也会出现乱码,这常见于相似的编码之间。
事实上,有些被人们视为等价的编码格式仍有细微差别。例如,ISO 8859-1(Latin1)标准起草时,微软也在开发码页1252(西欧语言),且先于ISO 8859-1完成。Windows-1252是ISO 8859-1的超集,包含C1范围内额外的可打印字符。若将Windows-1252编码的文本声明为ISO 8859-1并发送,则接收端很可能无法完全正确地显示文本。类似地,IANA将CP936作为GBK的别名,但GBK为中国官方规范,而CP936事实上由微软维护,因此两者仍有细微差异(但不如CP950和BIG5的差异大)。
很多仍在使用的编码都与彼此部分兼容,且将ASCII作为公共子集。因为ASCII文本不受这些编码格式的影响,用户容易误认为他们在使用ASCII编码,而将实际使用的ASCII超集声明为"ASCII"。也许为了简化,即使在学术文献中,也能发现"ASCII"被当作不兼容Unicode的编码格式,而文中"ASCII"其实是Windows-1252编码,"Unicode"其实是UTF-8编码(UTF-8向后兼容ASCII)。
1.5.3 过度指定编码格式
多层协议中,当每层都试图根据不同信息指定编码格式时,最不确定的信息可能会误导接受者。例如,Web服务器通过HTTP服务静态HTML文件时,可用以下任一方式将字符集通知客户端:
- 以HTTP标头。这可基于服务器配置或由服务器上运行的应用程序控制。
- 以文件中的HTML元标签(http-equiv或charset)或XML声明的编码属性。这是作者保存该文件时期望使用的编码。
- 以文件中的BOM标记。这是作者的编辑器保存文件时实际使用的编码。除非发生意外的编码转换(如以一种编码打开而以另一种编码保存),该信息将是正确的。 显然,当任一方式出现差错,而客户端又依赖该方式确定编码格式时,就会导致乱码产生。
1.5.4 解决方案
应用程序使用UTF-8作为默认编码时互通性更高,因为UTF-8使用广泛且向后兼容US-ASCII。UTF-8可通过简单的算法直接识别,因此设计良好的软件可以避免混淆UTF-8和其他编码。
现代浏览器和字处理器通常支持许多字符编码格式。浏览器通常允许用户即时更改渲染引擎的编码设置,而文字处理器允许用户打开文件时选择合适的编码。这需要用户进行一些试错,以找到正确的编码。
当程序支持的字符编码种类过少时,用户可能需要更改操作系统的编码设置以匹配该程序的编码。然而,更改系统范围的编码设置可能导致已存在的程序出现乱码。在Windows XP或更高版本的系统中,用户可以使用Microsoft AppLocale,以改变单个程序的区域设置。
当然,出现乱码时用户也可手工或编程恢复原始文本,详见本文"2.5 处理中文乱码"节,或《》一文。
二. Python2.7字符编码
因字符编码因系统而异,而本节代码实例较多,故首先指明运行环境,以免误导读者。
可通过以下代码获取当前系统的字符编码信息:
#coding=utf-8 import sys, localedef SysCoding(): fmt = '{0}: {1}' #当前系统所使用的默认字符编码 print fmt.format('DefaultEncoding ', sys.getdefaultencoding()) #转换Unicode文件名至系统文件名时所用的编码('None'表示使用系统默认编码) print fmt.format('FileSystemEncoding ', sys.getfilesystemencoding()) #默认的区域设置并返回元祖(语言, 编码) print fmt.format('DefaultLocale ', locale.getdefaultlocale()) #用户首选的文本数据编码(猜测结果) print fmt.format('PreferredEncoding ', locale.getpreferredencoding()) #解释器Shell标准输入字符编码 print fmt.format('StdinEncoding ', sys.stdin.encoding) #解释器Shell标准输出字符编码 print fmt.format('StdoutEncoding ', sys.stdout.encoding)if __name__ == '__main__': SysCoding() 作者测试所用的Windows XP主机字符编码信息如下:
DefaultEncoding : asciiFileSystemEncoding : mbcsDefaultLocale : ('zh_CN', 'cp936')PreferredEncoding : cp936StdinEncoding : cp936StdoutEncoding : cp936 如无特殊说明,本节所有代码片段均在这台Windows主机上执行。
注意,Windows NT+系统中,文件名本就为Unicode编码,故不必进行编码转换。但getfilesystemencoding()函数仍返回'mbcs',以便应用程序使用该编码显式地将Unicode字符串转换为用途等同文件名的字节串。注意,"mbcs"并非某种特定的编码,而是根据设定的Windows系统区域不同,指代不同的编码。例如,在简体中文Windows默认的区域设定里,"mbcs"指代GBK编码。
作为对比,其他两台Linux主机字符编码信息分别为:
#Linux 1DefaultEncoding : asciiFileSystemEncoding : UTF-8DefaultLocale : ('zh_CN', 'utf')PreferredEncoding : UTF-8StdinEncoding : UTF-8StdoutEncoding : UTF-8#Linux 2DefaultEncoding : asciiFileSystemEncoding : ANSI_X3.4-1968 #ASCII规范名DefaultLocale : (None, None)PreferredEncoding : ANSI_X3.4-1968StdinEncoding : ANSI_X3.4-1968StdoutEncoding : ANSI_X3.4-1968 可见,StdinEncoding、StdoutEncoding与FileSystemEncoding保持一致。这就可能导致Python脚本编辑器和解释器(CPython 2.7)的代码运行差异,后文将会给出实例。此处先引用Python帮助文档中关于stdin和stdout的描述:
stdin is used for all interpreter input except for scripts but including calls to input() and raw_input(). stdout is used for the output of print and expression statements and for the prompts of input() and raw_input(). The interpreter's own prompts and (almost all of) its error messages go to stderr.
可见,在Python Shell里输入中文字符串时,该字符串为cp936编码,即gbk;当print或raw_input()向Shell输出中文字符串时,该字符串按照cp936解码。
通过sys.setdefaultencoding()可修改当前系统所使用的默认字符编码。例如,在python27的Lib\site-packages目录下新建sitecustomize.py脚本,内容为:
#encoding=utf8 import sysreload(sys)sys.setdefaultencoding('utf8') 重启Python解释器后执行sys.getdefaultencoding(),会发现默认编码已改为UTF-8。多次重启之后仍有效,这是因为Python启动时自动调用该文件设置系统默认编码。而在作者的环境下,无论是Shell执行还是源代码中添加上述语句,均无法修改系统默认编码,反而导致sys模块功能异常。考虑到修改系统默认编码可能导致诡异问题,且会破坏代码可一致性,故不建议作此修改。
2.1 str和unicode类型
Python中有两种字符串类型,分别是str和unicode,它们都由抽象类型basestring派生而来。str字符串其实是字节组成的序列,unicode字符串则表示为unicode类型的实例,可视为字符的序列(对应C语言里真正的字符串)。
Python内部以16比特或32比特的整数表示Unicode字符串,这取决于Python解释器的编译方式。可通过sys模块maxunicode变量值判断当前所使用的Unicode类型:
>>> import sys; print sys.maxunicode65535
该变量表示支持的最大Unicode码点。其值为65535时表示Unicode字符以UCS-2存储;值为1114111时表示Unicode字符以UCS-4存储。注意,上述示例为求简短将多条语句置于一行,实际编码中应避免如此。
unicode(string[, encoding, errors])函数可根据指定的encoding将string字节序列转换为Unicode字符串。若未指定encoding参数,则默认使用ASCII编码(大于127的字符将被视为错误)。errors参数指定转换失败时的处理方式。其缺省值为'strict',即转换失败时触发UnicodeDecodeError异常。errors参数值为'ignore'时将忽略无法转换的字符;值为'replace'时将以U+FFFD字符(REPLACEMENT CHARACTER)替换无法转换的字符。举例如下:
>>> unicode('abc'+chr(255)+'def', errors='strict')UnicodeDecodeError: 'ascii' codec can't decode byte 0xff in position 3: ordinal not in range(128)>>> unicode('abc'+chr(255)+'def', errors='ignore')u'abcdef'>>> unicode('abc'+chr(255)+'def', errors='replace')u'abc\ufffddef' 方法.encode([encoding], [errors='strict'])可根据指定的encoding将Unicode字符串转换为字节序列。而.decode([encoding], [errors])根据指定的encoding将字节序列转换为Unicode字符串,即使用该编码方式解释字节序列。errors参数若取缺省值'strict',则编码和解码失败时会分别触发UnicodeEncodeError和UnicodeDecodeError异常。注意,unicode(str, encoding)与str.decode(encoding)是等效的。
当方法期望Unicode字符串,而实际编码为字节序列时,Python会先使用默认的ASCII编码将字节序列转换为Unicode字符串。例如:
>>> repr('ab' + u'cd')"u'abcd'">>> repr('abc'.encode('gbk'))"'abc'">>> repr('中文'.encode('gbk'))UnicodeDecodeError: 'ascii' codec can't decode byte 0xd6 in position 0: ordinal not in range(128) 在字符串拼接前,Python通过'ab'.decode(sys.getdefaultencoding())将'ab'转换为u'ab',然后将两个Unicode字符串合并。在中文编码前,Python试图通过类似的方式对'中文'解码,但sys.stdin(gbk)编码形式的字节序列\xd6\xd0\xce\xc4显然超出ASCII范围,因此触发UnicodeDecodeError。
若要将一个str类型转换成特定的编码形式(如utf-8、gbk等),可先将其转为Unicode类型,再从Unicode转为特定的编码形式。例如:
>>> def ParseStr(s): print '%s: %s(%s), Len: %s' %(type(s), s, repr(s), len(s))>>> zs = '肖'; ParseStr(zs): 肖('\xd0\xa4'), Len: 2>>> import sys; zs_u = zs.decode(sys.stdin.encoding)>>> ParseStr(zs_u) : 肖(u'\u8096'), Len: 1>>> zs_utf = zs_u.encode('utf8')>>> ParseStr(zs_utf) : 肖('\xe8\x82\x96'), Len: 3
其中,'肖'为Shell标准输入的中文字符,编码为cp936(sys.stdin.encoding)。经过解码和编码后,'肖'从cp936编码正确转换为utf-8编码。
除type()外,还可用isinstance()判断字符串类型:
>>> isinstance(zs, str), isinstance(zs, unicode), isinstance(zs, basestring)(True, False, True)>>> isinstance(zs_u, str), isinstance(zs_u, unicode), isinstance(zs_u, basestring)(False, True, True)
通过以下代码可查看Unicode字符名、类别等信息:
from unicodedata import category, namedef ParseUniChar(uni): for i, c in enumerate(uni): print '%2d U+%04X [%s]' %(i, ord(c), category(c)), print name(c, 'Unknown').title()
执行ParseUniChar(u'项ç®äC¿¼')后结果如下:
0 U+00E9 [Ll] Latin Small Letter E With Acute 1 U+00A1 [Po] Inverted Exclamation Mark 2 U+00B9 [No] Superscript One 3 U+00E7 [Ll] Latin Small Letter C With Cedilla 4 U+009B [Cc] Unknown 5 U+00AE [So] Registered Sign 6 U+00E4 [Ll] Latin Small Letter A With Diaeresis 7 U+00AD [Cf] Soft Hyphen 8 U+0043 [Lu] Latin Capital Letter C 9 U+00BF [Po] Inverted Question Mark10 U+00BC [No] Vulgar Fraction One Quarter
其中,类别缩写'Ll'表示"字母,小写(Letter, lowercase)",'Po'表示"标点,其他(Punctuation, other)",等等。详见。
2.2 源码字符串常量(Literals)
Python源码中,Unicode字符串常量书写时添加'u'或'U'前缀,如u'abc'。当源代码文件编码格式为utf-8时,u'中'等效于'中'.decode('utf8');当源代码文件编码格式为gbk时,u'中'等效于'中'.decode('gbk')。换言之,源文件的编码格式决定该源文件中字符串常量的编码格式。
注意,不建议使用from __future__ import unicode_literals特性(可免除Unicode字符串前缀'u'),这会引发兼容性问题。
Unicode字符串使得中文更容易处理,参考以下实例:
>>> s = '中wen'; su = u'中wen'>>> print repr(s), len(s), repr(su), len(su)'\xd6\xd0wen' 5 u'\u4e2dwen' 4>>> print s[0], su[0]Ö 中
可见,Unicode字符串长度以字符为单位,故len(su)为4,且su[0]对应第一个字符"中"。相比之下,s[0]截取"中"的第一个字节,即0xD6,该值正好对应中的"Ö"。
在源代码文件中,若字符串常量包含ASCII(Python脚本默认编码)以外的字符,则需要在文件首行或第二行声明字符编码,如#-*- coding: utf-8 -*-。实际上,Python只检查注释中的coding: name或coding=name,且字符编码通常还有,因此也可写为#coding:utf-8或#coding=u8。
若不声明字符编码,则字符串常量包含非ASCII字符时,将无法保存源文件。若声明的字符编码不适用于非ASCII字符,则会触发无效编码的I/O Error,并提示保存为带BOM的UTF-8文件 。保存后,源文件中的字符串常量将以UTF-8编码,无论编码声明如何。而此时再运行,会提示存在语法错误,如"encoding problem: gbk with BOM"。所以,务必确保源码声明的编码与文件实际保存时使用的编码一致。
此外,源文件里的非ASCII字符串常量,应采用添加Unicode前缀的写法,而不要写为普通字符串常量。这样,该字符串将为Unicode编码(即Python内部编码),而与文件及终端编码无关。参考如下实例:
#coding: u8print u'汉字', unicode('汉字','u8'), repr(u'汉字')print '汉字', repr('汉字')print '中文', repr('中文')import syssi = raw_input('汉字$')print si, repr(si),print si.decode(sys.stdin.encoding),print repr(si.decode(sys.stdin.encoding)) 运行后Shell里的结果如下:
汉字 汉字 u'\u6c49\u5b57'姹夊瓧 '\xe6\xb1\x89\xe5\xad\x97'中文 '\xe4\xb8\xad\xe6\x96\x87'姹夊瓧$汉字汉字 '\xba\xba\xd7\xd6' 汉字 u'\u6c49\u5b57'
显然,raw_input()的提示输出编码为cp936,因此误将源码中utf-8编码的'汉字'按照cp936输出为'姹夊瓧';raw_input()的输入编码也为cp936,这从repr和解码结果可以看出。
注意,'汉字'被错误输出,u'汉字'却能正常输出。这是因为,当Python检测到输出与终端连接时,设置sys.stdout.encoding属性为终端编码。print会自动将Unicode参数编码为str输出。若Python检测不到输出所期望的编码,则设置sys.stdout.encoding属性为None并调用ASCII codec(默认编码)强制将Unicode字符串转换为字节序列。
这种处理会导致比较有趣的现象。例如,将以下代码保存为test.py:
# -*- coding: utf-8 -*-import sys; print 'Enc:', sys.stdout.encodingsu = u'中文'; print su
在cmd命令提示符中分别运行python test.py和python test.py > test.txt,结果如下:
E:\PyTest\stuff>python test.pycp936中文E:\PyTest\stuff>python test.py > test.txtUnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
打开test.txt文件,可看到内容为"Enc: None"。这是因为,print到终端控制台时Python会自动调用ASCII codec(默认编码)强制转换编码,而write到文件时则不会。将输出语句改为print su.encode('utf8')即可正确写入文件。
最后,借助sys.stdin.encoding属性,可编写小程序显示汉字的主流编码形式。如下所示(未考虑错误处理):
#!/usr/bin/python#coding=utf-8def ReprCn(): strIn = raw_input('Enter Chinese: ') import sys encoding = sys.stdin.encoding print unicode(strIn, encoding), '->' print ' Unicode :', repr(strIn.decode(encoding)) print ' UTF8 :', repr(strIn.decode(encoding).encode('utf8')) strGbk = strIn.decode(encoding).encode('gbk') strQw = ''.join([str(x) for x in ['%02d'%(ord(x)-0xA0) for x in strGbk]]) print ' GBK :', repr(strGbk) print ' QuWei :', strQwif __name__ == '__main__': ReprCn() 以上程序保存为reprcn.py后,在控制台里执行python reprcn.py命令,并输入目标汉字:
[wangxiaoyuan_@localhost ~]$ python reprcn.py Enter Chinese: 汉字汉字 -> Unicode : u'\u6c49\u5b57' UTF8 : '\xe6\xb1\x89\xe5\xad\x97' GBK : '\xba\xba\xd7\xd6' QuWei : 26265554
2.3 读写Unicode数据
在写入磁盘文件或通过套接字发送前,通常需要将Unicode数据转换为特定的编码;从磁盘文件读取或从套接字接收的字节序列,应转换为Unicode数据后再处理。
这些工作可以手工完成。例如:使用内置的open()方法打开文件后,将read()读取的str数据,按照文件编码格式进行decode();write()写入前,将Unicode数据按照文件编码格式进行encode(),或将其他编码格式的str数据先按该str的编码decode()转换为Unicode数据,再按照文件编码格式encode()。若直接将Unicode数据传入write()方法,Python将按照源代码文件声明的字符编码进行encode()后再写入。
这种手工转换的步骤可简记为"due",即:
1) Decode early(将文件内容转换为Unicode数据) 2) Unicode everywhere(程序内部处理都用Unicode数据) 3) Encode late(存盘或输出前encode回所需的编码)然而,并不推荐这种手工转换。对于多字节编码(一个Unicode字符由多个字节表示),若以块方式读取文件,如一次读取1K字节,可能会切割开同属一个Unicode字符的若干字节,因此必须对每块末尾的字节做错误处理。一次性读取整个文件内容后再解码固然可以解决该问题,但这样就无法处理超大的文件,因为内存中需要同时存储已编码字节序列及其Unicode版本。
解决方法是使用codecs模块,该模块包含open()、read()和write()等方法。其中,open(filename, mode='rb', encoding=None, errors='strict', buffering=1)按照指定的编码打开文件。若encoding参数为None,则返回接受字节序列的普通文件对象;否则返回一个封装对象,且读写该对象时数据编码会按需自动转换。
Windows记事本以非Ansi编码保存文件时,会在文件开始处插入Unicode字符U+FEFF作为字节顺序标记(BOM),以协助文件内容字节序的自动检测。例如,以utf-8编码保存文件时,文件开头被插入三个不可见的字符(0xEF 0xBB 0xBF)。读取文件时应手工剔除这些字符:
import codecsfileObj = codecs.open(r'E:\PyTest\data_utf8.txt', encoding='utf-8')uContent = fileObj.readline()print 'First line +', repr(uContent)#剔除utf-8 BOM头uBomUtf8 = unicode(codecs.BOM_UTF8, "utf8")print repr(codecs.BOM_UTF8), repr(uBomUtf8)if uContent.startswith(uBomUtf8): uContent = uContent.lstrip(uBomUtf8)print 'First line -', repr(uContent)fileObj.close()
其中,data_utf8.txt为记事本以utf-8编码保存的文件。执行结果如下:
First line + u'\ufeffabc\r\n''\xef\xbb\xbf' u'\ufeff'First line - u'abc\r\n'
使用codecs.open()创建文件时,若编码指定为utf-16,则BOM会自动写入文件,读取时则自动跳过。而编码指定为utf-8、utf-16le或utf-16be时,均不会自动添加和跳过BOM。注意,编码指定为utf-8-sig时行为与utf-16类似。
2.4 Unicode文件名
现今的主流操作系统均支持包含任意Unicode字符的文件名,并将Unicode字符串转换为某种编码。例如,Mac OS X系统使用UTF-8编码;而Windows系统使用可配置的编码,当前配置的编码在Python中表示为"mbcs"(即Ansi)。在Unix系统中,可通过环境变量LANG或LC_CTYPE设置唯一的文件系统编码;若未设置则默认编码为ASCII。
os模块内的函数也接受Unicode文件名。中规定:
当open函数的
posix模块包含chdir、listdir、mkdir、open、remove、rename、rmdir、stat和_getfullpathname等函数。它们直接使用Unicode编码的文件和目录名参数,而不再转换(为filename参数为Unicode编码时,文件对象的name属性也为Unicode编码。文件对象的表达,即repr(f),将显示Unicode文件名。mbcs编码)。对rename函数而言,当任一参数为Unicode编码时触发上述行为,且使用默认编码将另一参数转换为Unicode编码。 当路径参数为Unicode编码时,listdir函数将返回一个Unicode字符串列表;否则返回字节序列列表。
注意,根据,不应直接import posix模块,而要import os模块。这样移植性更好。
os.listdir()方法比较特殊,参考以下实例:
>>> import os, sys; dir = r'E:\PyTest\调试'>>> os.listdir(unicode(dir, sys.stdin.encoding))[u'abcu.txt', u'dir1', u'\u6d4b\u8bd5.txt']>>> os.listdir(dir)['abcu.txt', 'dir1', '\xb2\xe2\xca\xd4.txt']>>> print os.listdir(dir)[2].decode(sys.getfilesystemencoding())测试.txt>>> fs = os.listdir(unicode(dir, sys.stdin.encoding))[2].encode('mbcs')>>> print open(os.path.join(dir, fs), 'r').read()abc中文 可见,Shell里输入的路径字符串常量中的中文字符以gbk编码,而文件系统也为gbk编码("mbcs"),因此调用os.listdir()时既可传入Unicode路径也可传入普通字节序列路径。对比之下,若在编码声明为utf-8的源代码文件中调用os.listdir(),因为路径字符串常量中的中文字符以utf-8编码,必须先以unicode(dir, 'u8')转换为Unicode字符串,否则会产生"系统找不到指定的路径"的错误。若要屏蔽编码差异,可直接添加Unicode前缀,即os.listdir(u'E:\\PyTest\\测试')。
2.5 处理中文乱码
本节主要讨论编码空间不兼容导致的中文乱码。
乱码可能发生在print输出、写入文件、数据库存储、网络传输、调用shell程序等过程中。解决方法分为事前事后:事前可约定相同的字符编码,事后则根据实际编码在代码侧重新转换。例如,简体中文Windows系统默认编码为GBK,Linux系统编码通常为en_US.UTF-8。那么,在跨平台处理文件前,可将Linux系统编码修改为zh_CN.UTF-8或zh_CN.GBK。
关于代码侧处理乱码,可参考一个简单的乱码产生与消除示例:
#coding=gbks = '汉字编码'print '[John(gb2312)] Send: %s(%s) --->' %(s, repr(s))su_latin = s.decode('latin1')print '[Mike(latin1)] Recv: %s(%s) ---messy!' %(su_latin, repr(su_latin)) 其中,John向Mike发送gb2312编码的字符序列,Mike收到后以本地编码latin1解码,显然会出现乱码。假设此时Mike获悉John以gb2312编码,但已无法访问原始字符序列,那么接下来该怎么消除乱码呢?根据前文的字符编码基础知识,可先将乱码恢复为字节序列,再以gbk编码去"解释"(解码)该字符序列,即:
s_latin = su_latin.encode('latin1')print '[Mike(latin1)] Convert (%s) --->' %repr(s_latin)su_gb = s_latin.decode('gbk')print '[Mike(latin1)] to gbk: %s(%s) ---right!' %(su_gb, repr(su_gb)) 将乱码的产生和消除代码合并,其运行结果如下:
[John(gb2312)] Send: 汉字编码('\xba\xba\xd7\xd6\xb1\xe0\xc2\xeb') --->[Mike(latin1)] Recv: ºº×Ö±àÂë(u'\xba\xba\xd7\xd6\xb1\xe0\xc2\xeb') ---messy![Mike(latin1)] Convert ('\xba\xba\xd7\xd6\xb1\xe0\xc2\xeb') --->[Mike(latin1)] to gbk: 汉字编码(u'\u6c49\u5b57\u7f16\u7801') ---right! 对于utf-8编码的源文件,将解码使用的'gbk'改为'utf-8'也可产生和恢复乱码("æ±åç¼ç ")。
可见,乱码消除的步骤为:1)将乱码字节序列转换为Unicode字符串;2)将该串"打散"为单字节数组;3)按照预期的编码规则将字节数组解码为真实的字符串。显然,"打散"的步骤既可编码转换也可手工解析。例如下述代码中的Dismantle()函数,就等效于encode('latin1'):
#coding=utf-8def Dismantle(messyUni): return ''.join([chr(x) for x in [ord(x) for x in messyUni]])def Dismantle2(messyUni): return reduce(lambda x,y: ''.join([x,y]), map(lambda x: chr(ord(x)), messyUni))su = u'ºº×Ö's1 = su.encode('latin1'); s2 = Dismantle(su); s3 = Dismantle2(su)print repr(su), repr(s1), repr(s2), repr(s3)print s1.decode('gbk'), s2.decode('gbk'), s3.decode('gbk')print u'æ°æµªå客'.encode('latin_1').decode('utf8')print u'惨事'.encode('cp1252').decode('utf8')print u'姹夊瓧缂栫爜'.encode('gbk').decode('utf8') 通过正确地编解码,可以完全消除乱码:
u'\xba\xba\xd7\xd6' '\xba\xba\xd7\xd6' '\xba\xba\xd7\xd6' '\xba\xba\xd7\xd6'汉字 汉字 汉字新浪博客惨事汉字编码
更进一步,考虑中文字符在不同编码间的转换场景。以几种典型的编码形式为例:
su = u'a汉字b'sl = su.encode('latin1', 'replace')su_g2l = su.encode('gbk').decode('latin1')su_glg = su.encode('gbk').decode('latin1').encode('latin1').decode('gbk')su_g2u = su.encode('gbk').decode('utf8', 'replace')su_gug = su.encode('gbk').decode('utf8', 'replace').encode('utf8').decode('gbk')su_u2l = su.encode('utf8').decode('latin1')su_u2g = su.encode('utf8').decode('gbk')print 'Convert %s(%s) ==>' %(su, repr(su))print ' latin1 :%s(0x%s)' %(sl, sl.encode('hex'))print ' gbk->latin1 :%s(%s)' %(su_g2l, repr(su_g2l))print ' g->l->g :%s(%s)' %(su_glg, repr(su_glg))print ' gbk->utf8 :%s(%s)' %(su_g2u, repr(su_g2u))print ' g->u->g :%s(%s)' %(su_gug, repr(su_gug))print ' utf8->latin1 :%s(%s)' %(su_u2l, repr(su_u2l))print ' utf8->gbk :%s(%s)' %(su_u2g, repr(su_u2g)) 运行结果如下:
Convert a汉字b(u'a\u6c49\u5b57b') ==> latin1 :a??b(0x613f3f62) gbk->latin1 :aºº×Öb(u'a\xba\xba\xd7\xd6b') g->l->g :a汉字b(u'a\u6c49\u5b57b') gbk->utf8 :a����b(u'a\ufffd\ufffd\ufffd\ufffdb') g->u->g :a锟斤拷锟斤拷b(u'a\u951f\u65a4\u62f7\u951f\u65a4\u62f7b') utf8->latin1 :aæ±åb(u'a\xe6\xb1\x89\xe5\xad\x97b') utf8->gbk :a姹夊瓧b(u'a\u59f9\u590a\u74e7b')
至此,可简单地总结中文乱码产生与消除的场景:
1) 一个汉字对应一个问号 当以latin1编码将Unicode字符串转换为字节序列时,由于一个Unicode字符对应一个字节,无法识别的Unicode字符将被替换为0x3F,即问号"?"。 2) 一个汉字对应两个EASCII或若干U+FFFD字符 当以gbk编码将Unicode字符串转换为字节序列时,由于一个Unicode字符对应两个字节,再以latin1编码转换为字符串时,将会出现两个EASCII字符。然而,这种乱码是可以恢复的。因为latin1是单字节编码,且覆盖单字节所有取值范围,以该编码传输、存储和转换字节流绝不会造成数据丢失。 当以utf-8编码转换为字符串时,结果会略为复杂。通常,gbk编码的字节序列不符合utf-8格式,无法识别的字节会被替换为U+FFFD"(REPLACEMENT CHARACTER)字符,再也无法恢复。以上示例中"汉字"对应四个U+FFFD,即一个汉字对应两个U+FFFD。但某些gbk编码恰巧"符合"utf-8格式,例如:>>> su_gbk = u'肖字辈'.encode('gbk')>>> s_utf8 = su_gbk.decode('utf-8', 'replace')>>> print su_gbk, repr(su_gbk), s_utf8, repr(s_utf8)肖字辈 '\xd0\xa4\xd7\xd6\xb1\xb2' Ф�ֱ� u'\u0424\ufffd\u05b1\ufffd' 由前文可知,utf-8规则可简记为(0),(110,10),(1110,10,10)。"肖字辈"以gbk编码转换的字节序列中,0xd0a4因符合(110,10)被解码为U+0424,对应斯拉夫(Cyrillic)大写字母Ф;0xd7d6因部分符合(110,10)规则,0xd7被替换为U+FFFD,并从0xd6开始继续解码;0xd6b1因符合(110,10)被解码为U+05b1,对应希伯来(Hebrew)非间距标记;最后,0xb2因不符合所有utf-8规则,被替换为U+FFFD。此时,"肖字辈"对应两个U+FFFD。也可看出,若原始字符串为"肖",其实是可以恢复乱码的。总体而言,将gbk编码的字节序列以utf-8解码时,可能导致无法恢复的错误。
3)两个汉字对应六个EASCII或三个其他汉字 当以utf-8编码将Unicode字符串转换为字节序列时,由于一个Unicode字符对应三个字节,再以latin1编码转换为字符串时,将会出现三个EASCII字符。当以gbk编码转换为字符串时,由于两个字节对应一个汉字,因此原始字符串中的两个汉字被转换为三个其他汉字。2.6 中文处理建议
Python2.x中默认编码为ASCII,而Python3中默认编码为Unicode。因此,如果可能应尽快迁移到Python3。否则,应遵循以下建议:
1) 源代码文件使用字符编码声明,且保存为所声明的编码格式。同一工程中的所有源代码文件也应使用和保存为相同的字符编码。若工程跨平台,应尽量统一为UTF-8编码。 2) 程序内部全部使用Unicode字符串,只在输出时转换为特定的编码。对于源码内的字符串常量,可直接添加Unicode前缀("u"或"U");对于从外部读取的字节序列,可按照"Decode early->Unicode everywhere->Encode late"的步骤处理。但按照"due"步骤手工处理文件时不太方便,可使用codecs.open()方法替代内置的open()。 此外,小段程序的编码问题可能并不明显,若能保证处理过程中使用相同编码,则无需转换为Unicode字符串。例如: >>> import re>>> for i in re.compile('测试(.*)').findall('测试一二三'): print i 一二三 3) 并非所有Python2.x内置函数或方法都支持Unicode字符串。这种情况下,可临时以正确的编码转换为字节序列,调用内置函数或方法完成操作后,立即以正确的编码转换为Unicode字符串。
4) 通过encode()和decode()编解码时,需要确定待转换字符串的编码。除显式约定外,可通过以下方法猜测编码格式:a.检测文件头BOM标记,但并非所有文件都有该标记;b.使用chardet.detect(str),但字符串较短时结果不准确;c.国际化产品最有可能使用UTF-8编码。 5) 避免在源码中显式地使用"mbcs"(别名"dbcs")和"utf_16"(别名"U16"或"utf16")的编码。 "mbcs"仅用于Windows系统,编码因当前系统ANSI码页而异。Linux系统的Python实现中并无"mbcs"编码,代码移植到Linux时会出现异常,如报告AttributeError: 'module' object has no attribute 'mbcs_encode'。因此,应指定"gbk"等实际编码,而不要写为"mbcs"。 "utf_16"根据操作系统原生字节序指代"utf_16_be"或"utf_16_le"编码,也不利于移植。 6) 不要试图编写可同时处理Unicode字符串和字节序列的函数,这样很容易引入缺陷。 7) 测试数据中应包含非ASCII(包括EASCII)字符,以排除编码缺陷。三. 参考资料
除前文已给出的链接外,本文还参考以下资料(包括但不限于):